
The goal of this assignment is to implement neural style transfer. We use a pretrained VGG19 model to extract features from the content and style images. We then optimize the input image to minimize the content loss and style loss.
After this, I implemented iterative "bells and whistles" improvements:
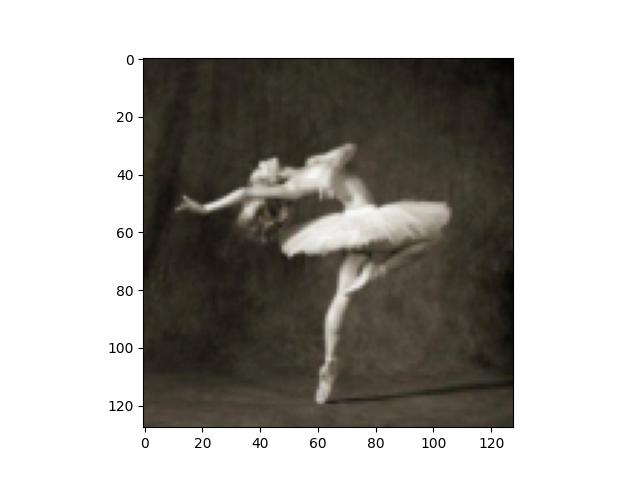
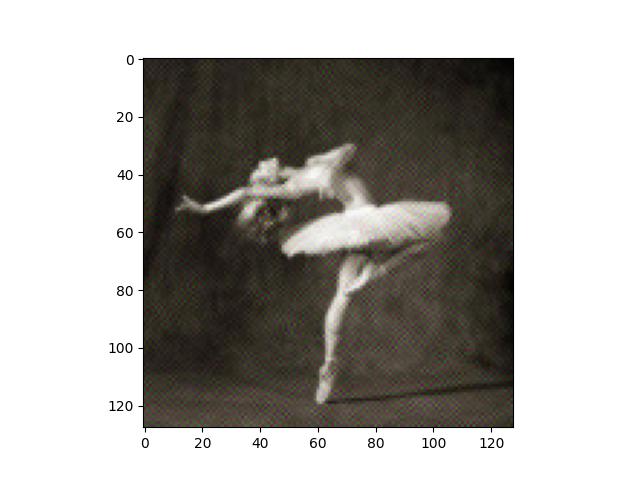
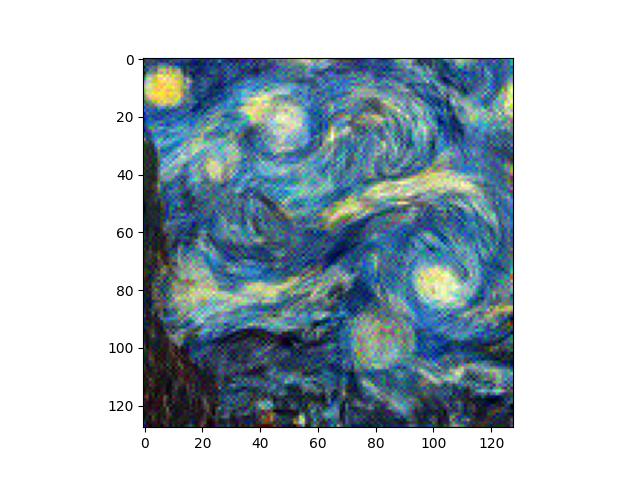
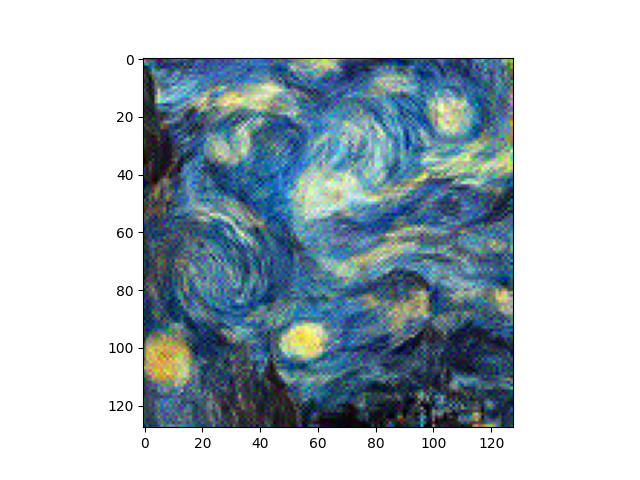
For this task, I implemented a simple reconstruction loss between an image and its reconstruction using MSE loss. The loss takes place after layers which a user can specify. I experiment with using different layers for the reconstruction loss location to see how different layers affect the reconstruction.
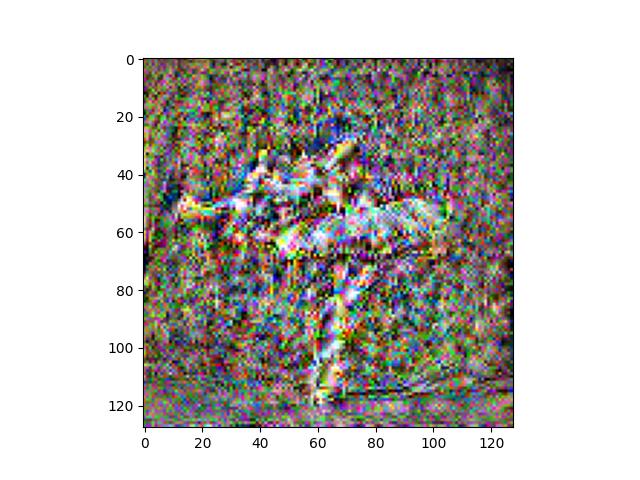
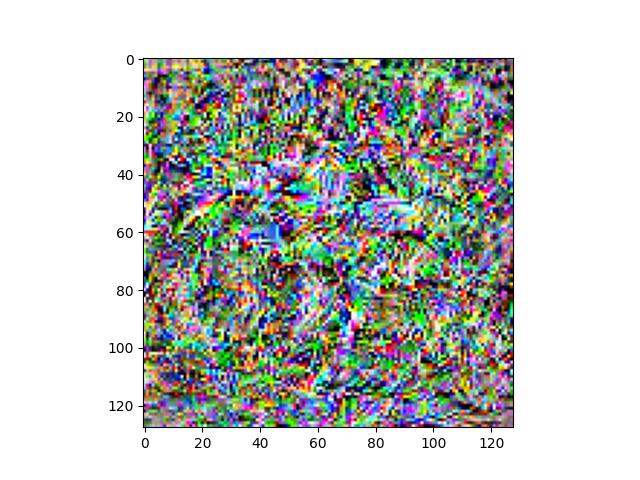

We can see here that the images get progressively more noisy as we move to deeper layers. This makes sense, as the higher frequency details are preserved in earlier layers. Low frequency, semantically meaningful qualities are preserved in later layers, but images can get quite noisy/blurry in the meantime. Using multiple layers can provide a mix of performance, but I believe that just using an earlier layer is sufficient quality-wise while also reducing complexity. I don't want to choose too early in the model though, otherwise, we will preserve too much of the high frequency details that we want replaced with a different style later.


As you can see, there's very little difference between the outputs of different noise. There's some hazy dots in the reconstruction difference, where I subtracted the reconstructed image from the original content image. They are not very noticeable. This shows that the reconstruction from different noises can get very close to the original content image.
The style loss finds the MSE loss between the gram matrix of the style image and the gram matrix of the input image. We minimize this to get the style of the input image to match the style of the style image.
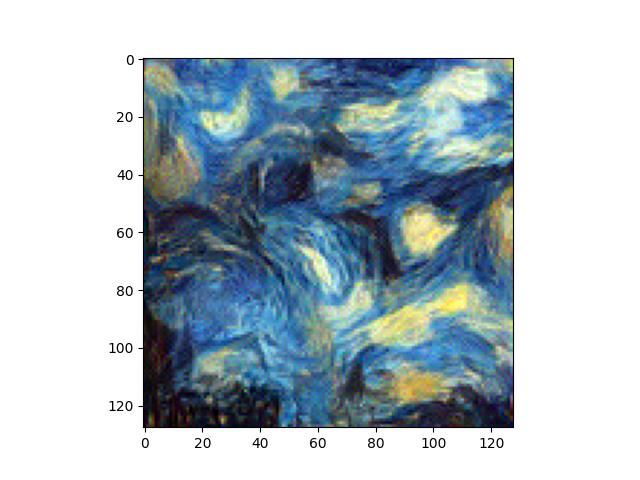
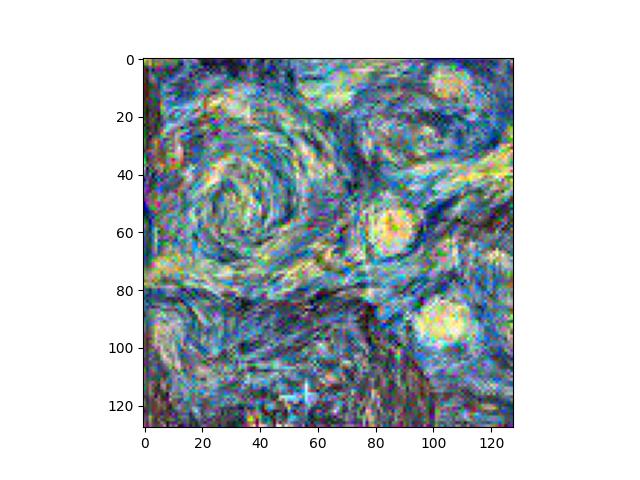
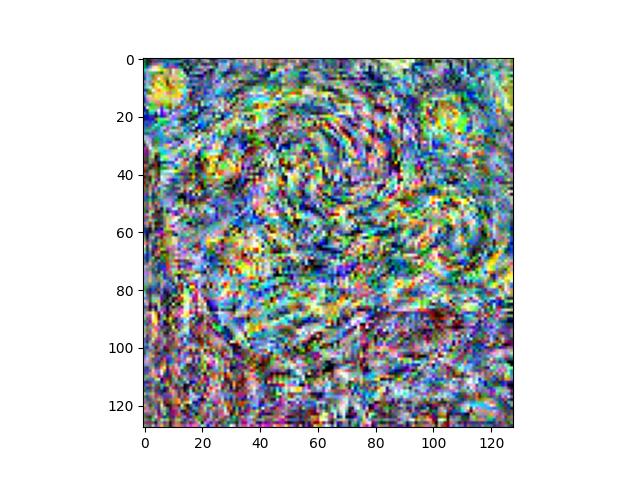
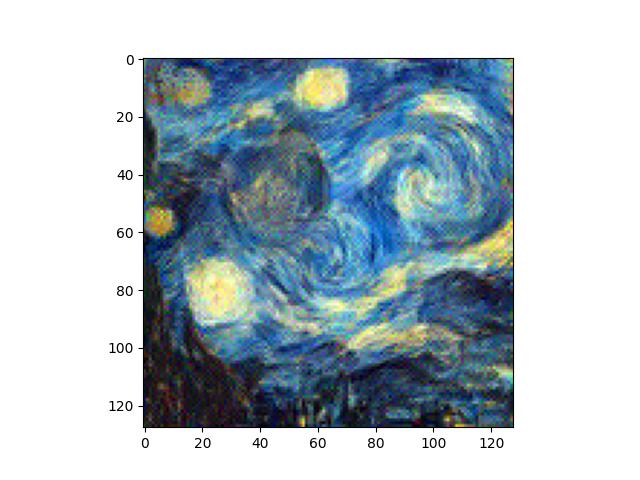
Here, we can see that earlier layers have better quality textures (high frequency details are better), but global details from the style image are not preserved. As we move to later layers, the global details are better preserved and begin showing up, but the textures and smaller details become quite distorted. I preferred a mix of the two, like style loss at conv layers 2, 4, 6, 8, and 10.
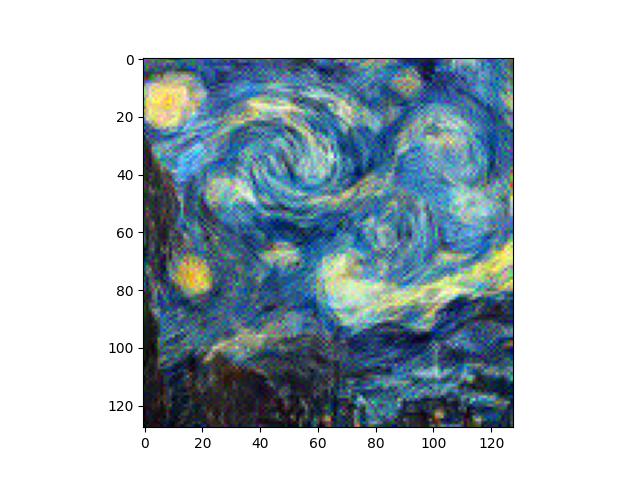
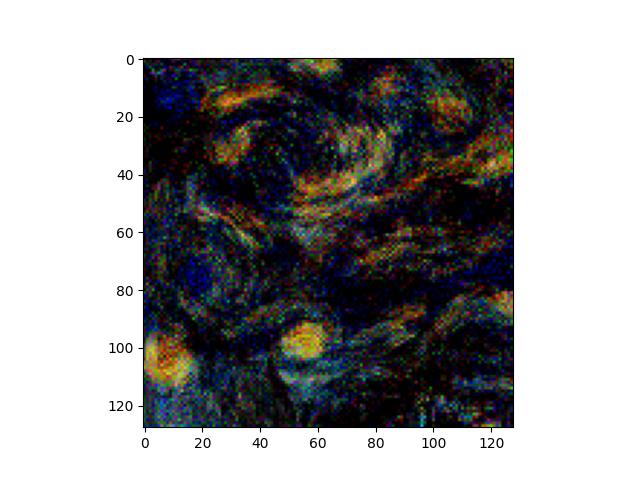
Again, different noise initializations produce outputs that are quite similar. That said, textures/styles are by nature, much higher frequency than content, so there is a more significant difference, which we can see when we subtract the two. Interestingly, the difference between the two synthesized textures looks quite nice itself.
As we had learned in class, style transfer loss uses a gram matrix to represent the style of the image in either a feature space or pixel space. I mainly used feature space, and we then minimized the image to match styles with a model's feature space's gram matrix after certain layers that a user can select.
For each image and style, some slight hyperparater tuning is need to get better outputs. However, I found that there was a good balance at:
For the most part, I only need to adjust the style weight to make the style influence heavier or lighter depending on the complexity of the content image. If the content image (like dancing) is easily overwhelmed by the style image (like starry night), then it is a good idea to reduce the style_weight to 1,000. For lighter styles, like picasso, the style_weight can be increased to 100,000/1,000,000. We will also see later that the quality of output also depends on the initialization approach, and some hyperparameters will only work well with noise initialization while others work well with content initialization.








Time when initializing with random noise: 720.0257666110992
Time when initializing with content image: 718.3290090560913
The times are extremely close, so there is not much of a difference. The content image initialization is always consistently faster though. It does make some sense that initializing with the content image should make the optimization faster, since we are closer to the optimal solution than random noise. However, we hardcoded the number of optimization steps, so closer starting point does not decrease the number of optimization operations. Additionally, when printing the loss, we see the loss drops below 1 within a few iterations. After this, the optimization is very similar between noise and content initialization. If I implemented some early stopping behavior which stopped iterations when the loss converged, we would probably see a much faster time for initialization with the content image.




Quality-wise, we can see that the images are much more faithful (color intensities are closer) to the original content image with content initialization. However, both are quite good. In some experiments, I also saw that the style transfer fails to converge with noise initialization. This is likely because the optimization is stuck in some other local minimum.
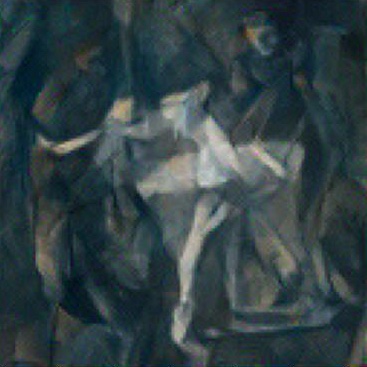









Video style transfer took quite a bit of work. First, I found an online repository that worked on a similar problem, but their model learns style transfer with a loss function that encourages temporal smoothness. The end result is similar to what we want, but it does not use optimization to accomplish this, which is what we want to do.
I used their pretrained SPyNet model to calculate the optical flow between frames. The transformation of the input image depending on the optical flow to the next frame is then used as an additional loss term in the optimization problem. The results (left) were not very good. After investigating, I found that the optical flow was pretty random looking, which meant the training did not have a good representative loss function to optimize on.
As a result, I utilized the more powerful DeepFlow2 to calculate the optical flow. With this, the style stabilized to a stronger degree. That said, there are a couple frames, where it seems that the optical flow is not calculated correctly, and the result is a radical change to the style, which causes the flashes you see. It should be noted that videos are very computationally expensive, so I did this with 128x128 frames, and only 4 seconds of video. In addition I reduced the optimization problem to 5 iterations per frame. Even with these changes, the results seem decent. The video I used is from a video of someone walking around London that I pulled from YouTube.



I first applied a naive approach, in which I simply masked out the content image at each iteration. It honestly looks quite decent. In comparison, I also utilized the implementation given in Controlling Perceptual Factors in Neural Style Transfer. This approach finds the activations that a mask corresponds to, and uses this to influence the gram matrix. This approach has a more involved loss function, but the results end up unsatisfactory in my opinion. I believe the reason for this comes from the fact that the cropped sky, is a uniform blue, so it does not have many characteristics for a style to transfer onto, resulting in a fairly bland pattern. That said, the edge of the mask is then able to contribute to the style transfer, and while not totally noticeable in this example, you'll see that there tends to be a gradient from the edge of the mask.

